
基于大数据的图书推荐系统系统(四)——数据统计
Statistics Recommender
第一个Dataloader模块记录之前没有把过程截图,我下面将离线数据统计模块的创建过程截图记录
此模块的前置条件:
- 第一步Dataloader成功存储数据
- 虚拟机安装完成MongoDB和Spark并且成功启动
创建子模块
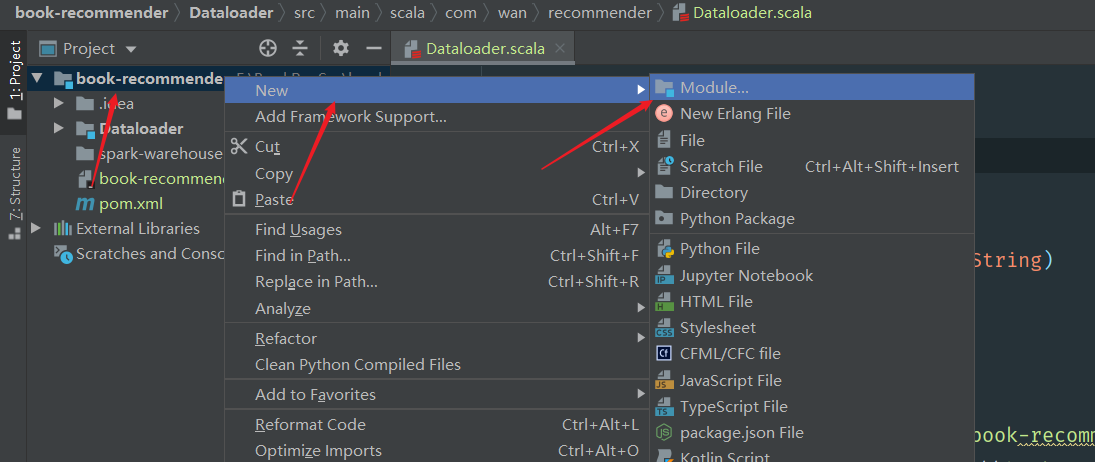
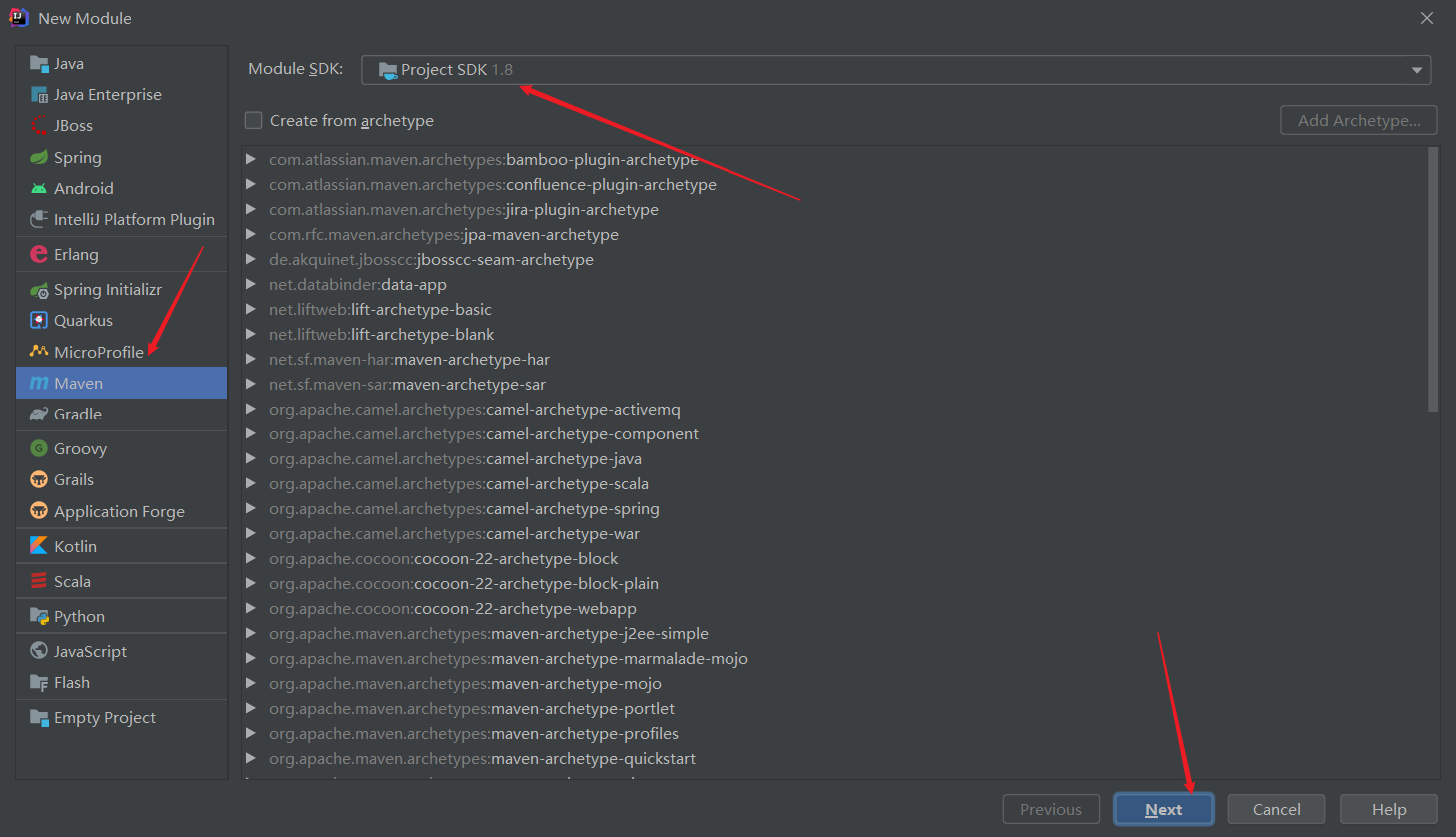
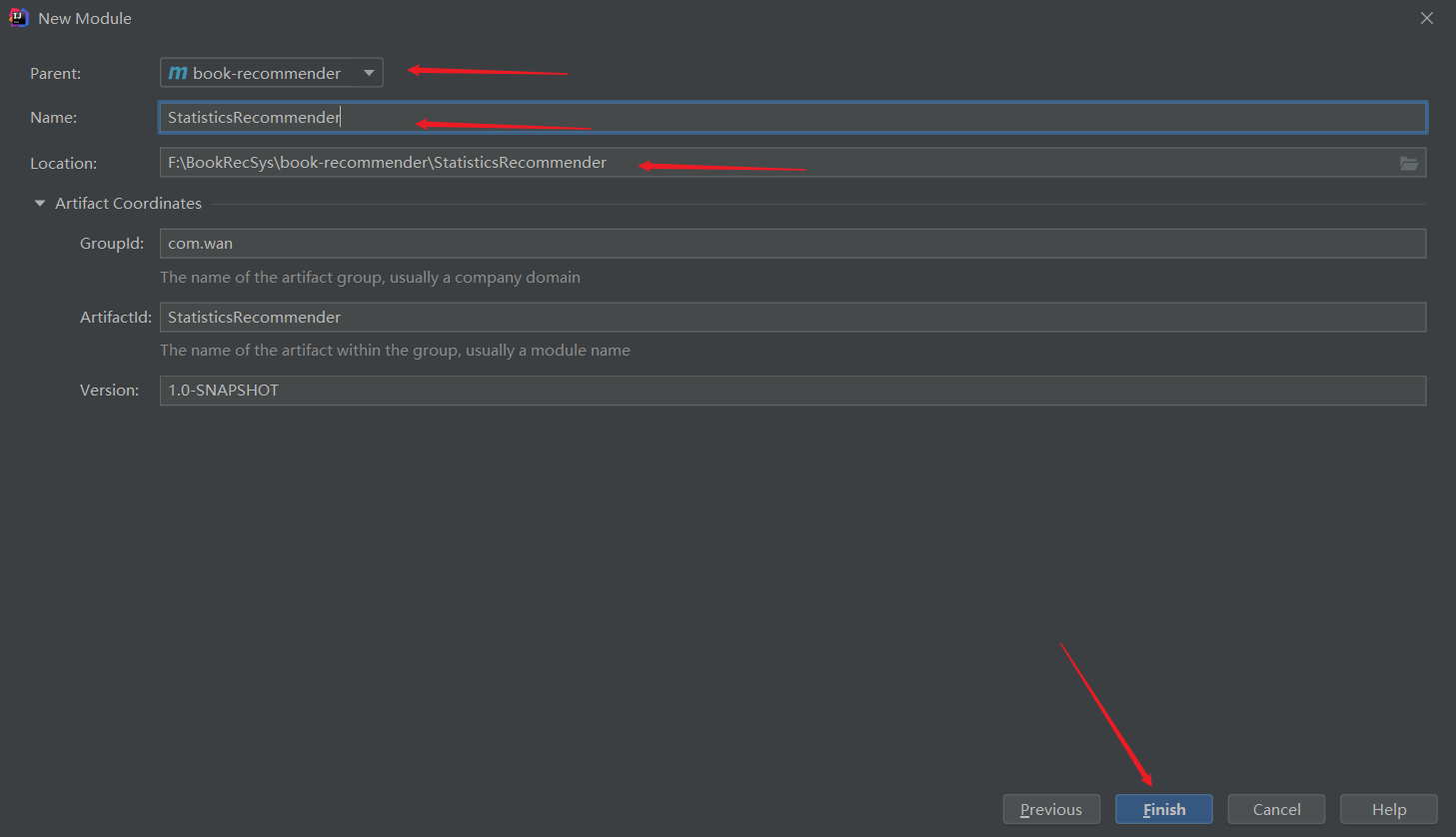
添加依赖
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>book-recommender</artifactId>
<groupId>com.wan</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>StatisticsRecommender</artifactId>
<dependencies>
<!-- Spark的依赖引入 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
</dependency>
<!-- 引入Scala -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
</dependency>
<!-- 加入MongoDB的驱动 -->
<!-- 用于代码方式连接MongoDB -->
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>casbah-core_2.11</artifactId>
<version>${casbah.version}</version>
</dependency>
<!-- 用于Spark和MongoDB的对接 -->
<dependency>
<groupId>org.mongodb.spark</groupId>
<artifactId>mongo-spark-connector_2.11</artifactId>
<version>${mongodb-spark.version}</version>
</dependency>
</dependencies>
<build>
<finalName>statisticsrecommender</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass>com.wan.statistics.StatisticsRecommender</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
</plugins>
</build>
</project>
配置日志文件
编码
StatisticsRecommender.scala1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68package com.wan.statistics
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* @author wanfeng
* @date 2021/3/13 10:36
*/
case class Rating(userId: Int, bookId: Int, score: Int)
case class MongoConfig(uri: String, db: String)
object StatisticsRecommender {
val MONGODB_RATING_COLLECTION = "Rating"
//定义统计表名
val RATE_MORE_BOOKS = "RateMoreBooks"
val AVERAGE_BOOKS = "AverageBooks"
def main(args: Array[String]): Unit = {
val config = Map(
"spark.cores" -> "local[*]",
"mongo.uri" -> "mongodb://192.168.2.88:27017/recommender",
"mongo.db" -> "recommender"
)
val sparkConf = new SparkConf().setMaster(config("spark.cores")).setAppName("StatisticsRecommender")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
implicit val mongoConfig = MongoConfig(config("mongo.uri"), config("mongo.db"))
val ratingDF = spark.read
.option("uri", mongoConfig.uri)
.option("collection", MONGODB_RATING_COLLECTION)
.format("com.mongodb.spark.sql")
.load()
.as[Rating]
.toDF()
ratingDF.createTempView("ratings")
//1. 历史热门书籍,按照评分个数统计
val rateMoreBooksDF = spark.sql("select bookId, count(bookId) as countNum from ratings group by bookId order by countNum desc")
storeDFInMongoDB(rateMoreBooksDF, RATE_MORE_BOOKS)
//2. 优质书籍
val averageBooksDF = spark.sql("select bookId, avg(score) as avgScore from ratings group by bookId order by avgScore desc")
storeDFInMongoDB(averageBooksDF, AVERAGE_BOOKS)
spark.stop()
}
def storeDFInMongoDB(df: DataFrame, collection_name: String)(implicit mongoConfig: MongoConfig): Unit = {
df.write
.option("uri", mongoConfig.uri)
.option("collection", collection_name)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
}
}展示工程结构与运行效果:
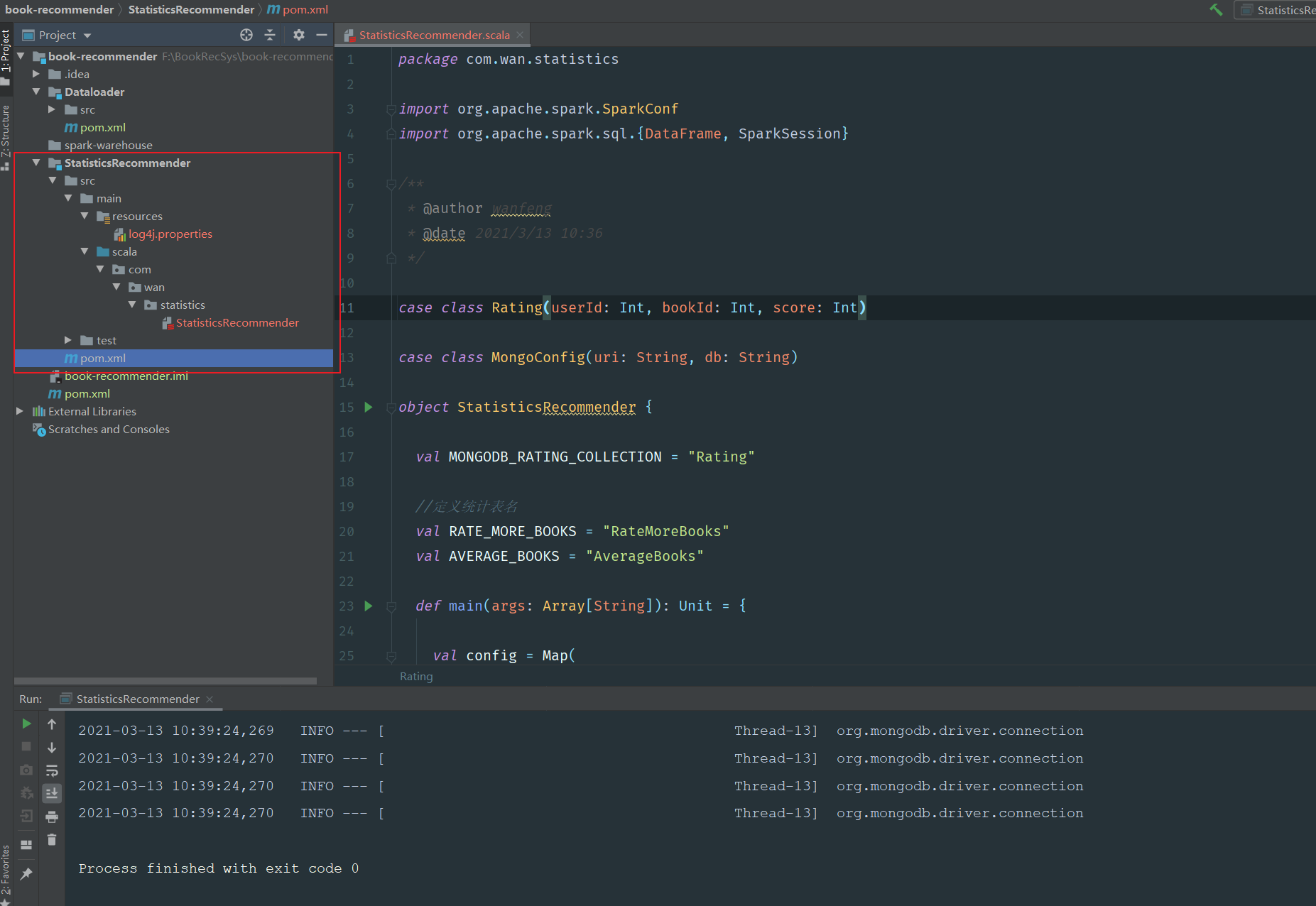
结束!


