
基于大数据的图书推荐系统系统(三)——数据加载与存储
Dataloader
此模块的前置条件:
- 本地有Maven、Java、Scala、IDEA环境
- 虚拟机安装完成MongoDB和Spark并且成功启动
- MongoDB可以不用建库建表,本地最好有一个MongoDB的可视化工具,我是用robo 3T,来验证MongoDB的远程连接和数据是否成功导入
- 以下步骤可能不太详细,参照我的项目结构以及代码灵活改动
新建父工程book-recommender
父工程只进行一些依赖的全局设置,不涉及具体编码,所以删除该目录下的
src目录为父工程添加全局依赖
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.wan</groupId>
<artifactId>book-recommender</artifactId>
<version>1.0-SNAPSHOT</version>
<modules>
<module>Dataloader</module>
</modules>
<packaging>pom</packaging>
<properties>
<log4j.version>1.2.17</log4j.version>
<slf4j.version>1.7.22</slf4j.version>
<mongodb-spark.version>2.0.0</mongodb-spark.version>
<casbah.version>3.1.1</casbah.version>
<redis.version>2.9.0</redis.version>
<kafka.version>0.10.2.1</kafka.version>
<spark.version>2.1.1</spark.version>
<scala.version>2.11.8</scala.version>
<jblas.version>1.2.1</jblas.version>
</properties>
<dependencyManagement>
<dependencies>
<!-- 引入Spark相关的Jar包 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-graphx_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<!-- 引入共同的日志管理工具 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>jcl-over-slf4j</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>${log4j.version}</version>
</dependency>
</dependencies>
<build>
<!--声明并引入子项目共有的插件-->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<!--所有的编译用JDK1.8-->
<configuration>
<source>1.8</source>
<target>1.8</target>
<!--<fork>true</fork>-->
<meminitial>512m</meminitial>
<maxmem>4096m</maxmem>
</configuration>
</plugin>
<!--maven的打包插件-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
<pluginManagement>
<plugins>
<!--该插件用于将scala代码编译成class文件-->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<!--绑定到maven的编译阶段-->
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</pluginManagement>
</build>
</project>
新建子模块Dataloader
为Dataloader模块添加依赖
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>book-recommender</artifactId>
<groupId>com.wan</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>Dataloader</artifactId>
<dependencies>
<!-- Spark的依赖引入 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
</dependency>
<!-- 引入Scala -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
</dependency>
<!-- 加入MongoDB的驱动 -->
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>casbah-core_2.11</artifactId>
<version>${casbah.version}</version>
</dependency>
<dependency>
<groupId>org.mongodb.spark</groupId>
<artifactId>mongo-spark-connector_2.11</artifactId>
<version>${mongodb-spark.version}</version>
</dependency>
</dependencies>
</project>
添加数据集文件和日志配置文件
Dataloader代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163package com.wan.recommender
import com.mongodb.casbah.commons.MongoDBObject
import com.mongodb.casbah.{MongoClient, MongoClientURI}
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SparkSession}
/*
* 书籍数据集
*
*"ISBN";"Book-Title";"Book-Author";"Year-Of-Publication";"Publisher";"Image-URL-S";"Image-URL-M";"Image-URL-L"
*"0195153448"; 书籍编号
*"Classical Mythology"; 书籍名称
*"Mark P. O. Morford"; 书籍作者
*"2002"; 书籍出版日期
*"Oxford University Press"; 书籍出版社
*"http://images.amazon.com/images/P/0195153448.01.THUMBZZZ.jpg"; 书籍封面链接
*"http://images.amazon.com/images/P/0195153448.01.MZZZZZZZ.jpg";
*"http://images.amazon.com/images/P/0195153448.01.LZZZZZZZ.jpg"
* */
case class Book(bookId: Int, bookTitle: String, bookAuthor: String, publishDate: String, press: String, bookImageUrl: String)
/*
* 评分数据集
*
* "User-ID";"ISBN";"Book-Rating"
"276725"; 用户ID
"034545104X"; 书籍编号
"0" 用户评分
* */
case class Rating(userId: Int, bookId: Int, score: Int)
/*
* MongoDB连接配置
* */
case class MongoConfig(uri: String, db: String)
object Dataloader {
//定义源文件地址
val BOOK_DATA_PATH = "F:\\BookRecSys\\book-recommender\\Dataloader\\src\\main\\resources\\BX-Books.csv"
val RATEING_DATA_PATH = "F:\\BookRecSys\\book-recommender\\Dataloader\\src\\main\\resources\\BX-Book-Ratings.csv"
//定义表名
val MONGODB_BOOK_COLLECTION = "Book"
val MONGODB_RATING_COLLECTION = "Rating"
def main(args: Array[String]): Unit = {
val config = Map(
"spark.cores" -> "local[*]",
"mongo.uri" -> "mongodb://192.168.2.88:27017/recommender",
"mongo.db" -> "recommender"
)
//创建一个sparkConfig
val sparkConf = new SparkConf().setMaster(config("spark.cores")).setAppName("DataLoader")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
//加载数据
val bookRDD = spark.sparkContext.textFile(BOOK_DATA_PATH)
val bookDF = bookRDD.map(item => {
val attr = item.split("\\;")
Book(
bookIdToInt(attr(0).replace("\"", "").trim()),
attr(1).replace("\"", "").trim(),
attr(2).replace("\"", "").trim(),
attr(3).replace("\"", "").trim(),
attr(4).replace("\"", "").trim(),
attr(7).replace("\"", "").trim()
)
}).toDF()
val ratingRDD = spark.sparkContext.textFile(RATEING_DATA_PATH)
val ratingDF = ratingRDD.map(item => {
val attr = item.split("\\;")
Rating(
attr(0).replace("\"", "").trim().toInt,
bookIdToInt(attr(1).replace("\"", "").trim()),
attr(2).replace("\"", "").trim().toInt
)
}).toDF()
implicit val mongoConfig = MongoConfig(config("mongo.uri"), config("mongo.db"))
storeDataInMongoDB(bookDF, ratingDF)
spark.stop()
}
def storeDataInMongoDB(bookDF: DataFrame, ratingDF: DataFrame)(implicit mongoConfig: MongoConfig): Unit = {
val mongoClient = MongoClient(MongoClientURI(mongoConfig.uri))
val bookCollection = mongoClient(mongoConfig.db)(MONGODB_BOOK_COLLECTION)
val ratingCollection = mongoClient(mongoConfig.db)(MONGODB_RATING_COLLECTION)
bookCollection.dropCollection()
ratingCollection.dropCollection()
bookDF.write
.option("uri", mongoConfig.uri)
.option("collection", MONGODB_BOOK_COLLECTION)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
ratingDF.write
.option("uri", mongoConfig.uri)
.option("collection", MONGODB_RATING_COLLECTION)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
bookCollection.createIndex(MongoDBObject("bookId" -> 1))
ratingCollection.createIndex(MongoDBObject("bookId" -> 1))
ratingCollection.createIndex(MongoDBObject("userId" -> 1))
mongoClient.close()
}
//源数据集中的bookId无法直接转化为Int,这里缩短长度并简单处理
def bookIdToInt(bookId: String): Int = {
var str: Array[Char] = bookId.toCharArray()
var res = ""
if (str(0).toInt > 1) {
res += '1'
}
if (str.length >= 10) {
for (i <- 1 until 10) {
if (!isIntByRegex(str(i))) {
str(i) = '1'
}
res += str(i)
}
} else {
for (i <- 0 until (str.length)) {
if (!isIntByRegex(str(i))) {
str(i) = '1'
}
res += str(i)
}
}
var resBookId = res.trim.toInt
resBookId
}
def isIntByRegex(s: Char) = {
val pattern = """^(\d+)$""".r
s match {
case pattern(_*) => true
case _ => false
}
}
}
最后展示工程结构与运行效果:
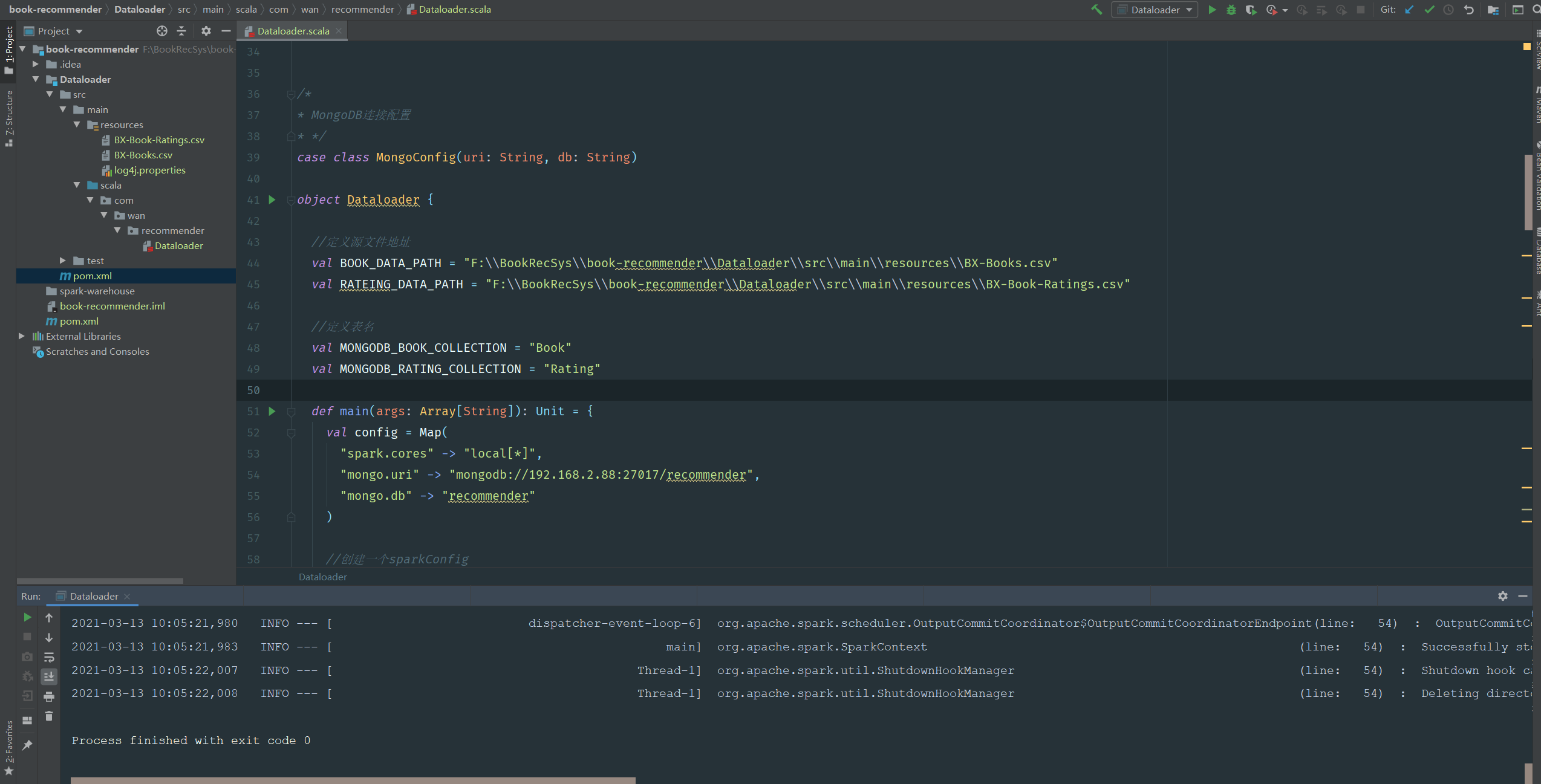
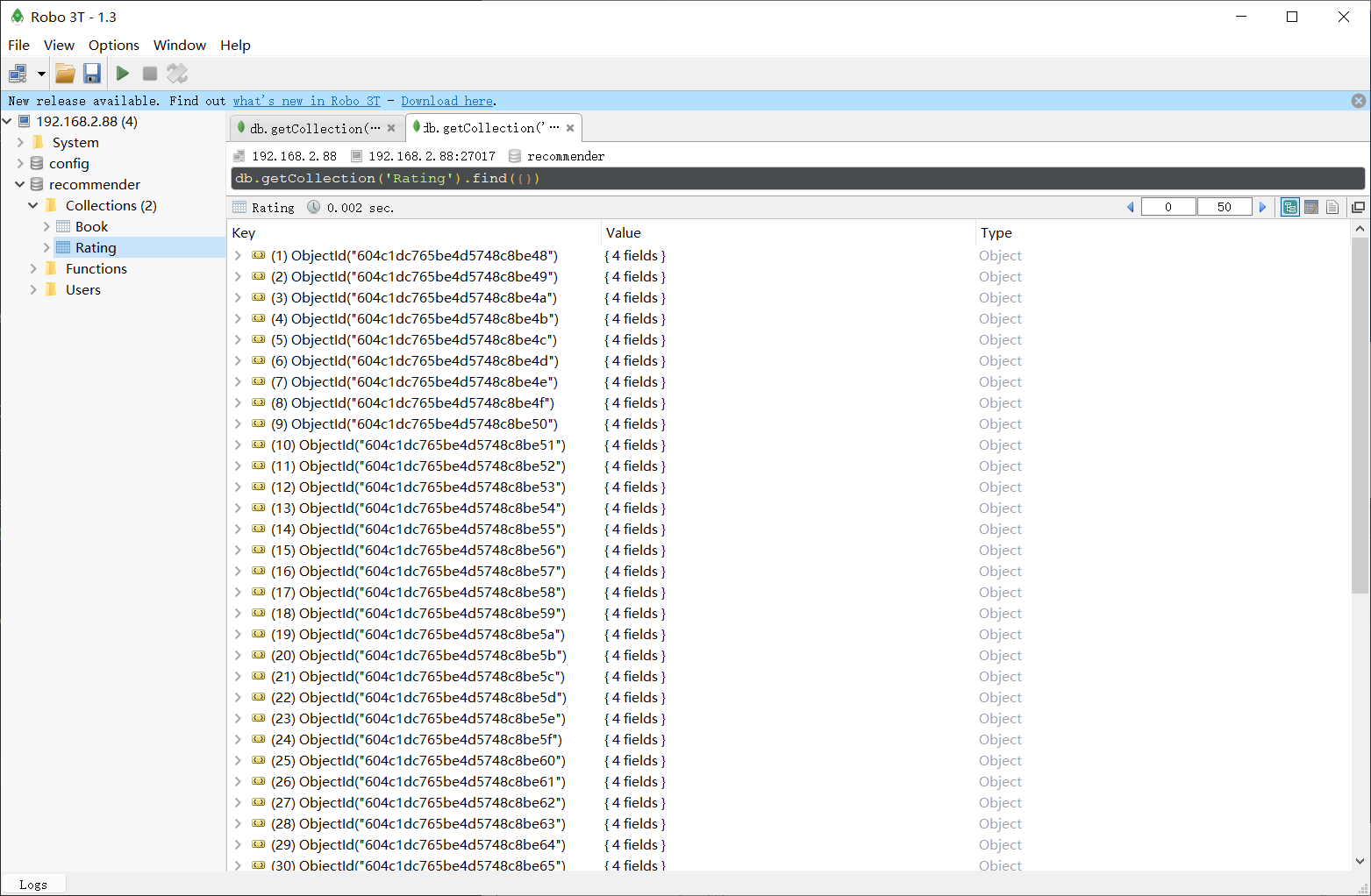
- 此模块遇见的问题参考我记录的
一些问题文档中2021.3.13 - 结束!


