
基于大数据的图书推荐系统系统(二)——软件安装
基本软件安装
1.安装MongoDB
参考菜鸟教程:Linux平台安装MongoDB
MongoDB下载网址:https://www.mongodb.com/try/download/community
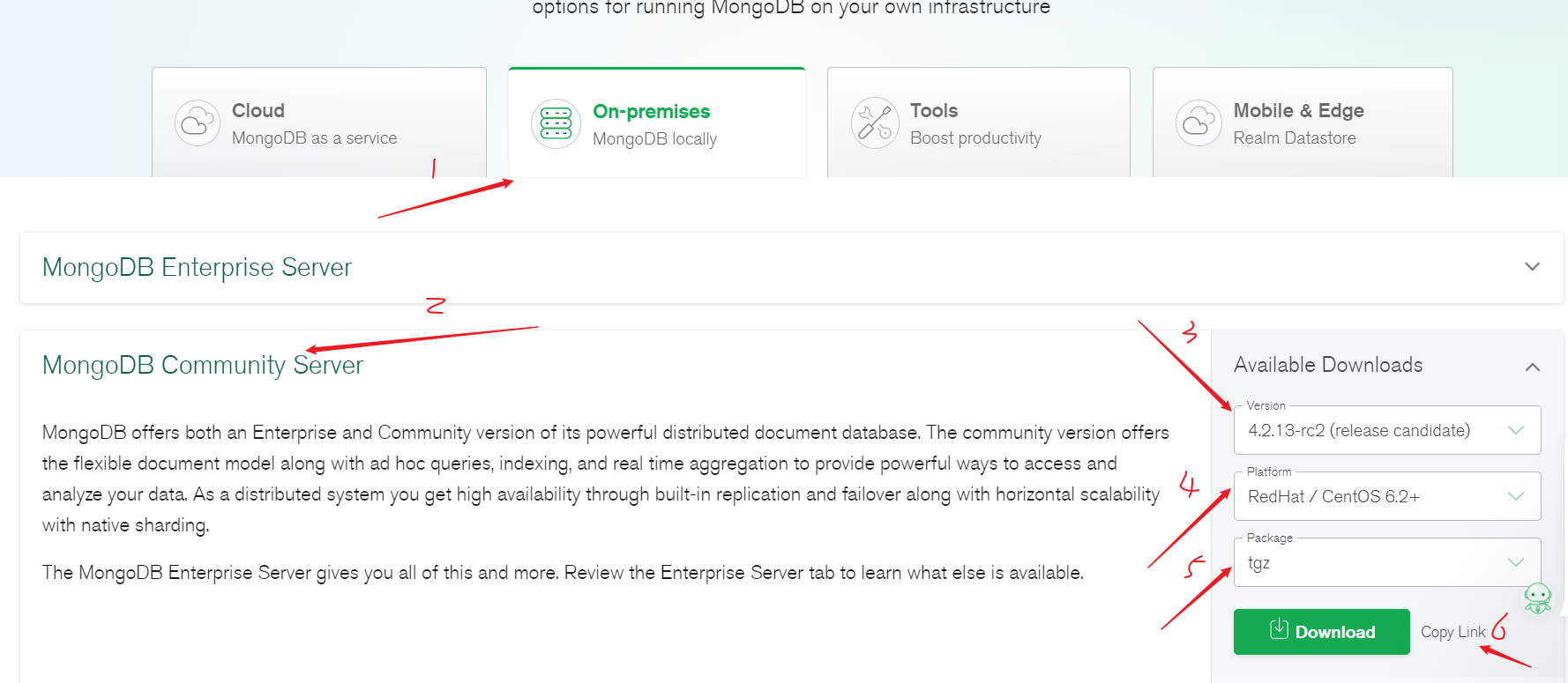
复制后的链接为:https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel62-4.2.13-rc2.tgz
具体操作如下:
1 | cd /usr/local |

2.卸载系统自带JDK
因为安装的CentOS 6.8自带的JDK版本为1.7,而Spark在2.2版本之后不再支持JDK1.7,所以需要重新安装JDK1.8
1.卸载JDK1.7
输入命令yum list installed | grep java就可以查看系统中的JDK,如图

卸载yum -y remove java-1.6.0-openjdk.x86_64,yum -y remove java-1.7.0-openjdk.x86_64
完成后,输入命令java -version会发现JDK已经完全卸载,接下来安装JDK1.8
2.安装JDK1.8
1.首先需要在Oracle的官网下载JDK1.8的安装包(官网下载需要注册账号),这里我本地有JDK1.8的包,直接上传到虚拟机中进行安装,上传过程略过,安装包位置在/usr/local/java
2.解压
tar -zxvf jdk-8u251-linux-x64.tar.gz
3.重命名
mv jdk1.8.0_251/ jdk
4.配置环境变量
vim /etc/profile
5.在文件末尾添加如下内容
1 | export JAVA_HOME=/usr/local/java/jdk |
6.保存退出后,使配置生效
source /etc/profile
7.再次输入java -version会出现相应的JDK版本信息,JDK安装完成!
3.安装Spark
Spark的下载官网:https://spark.apache.org/downloads.html
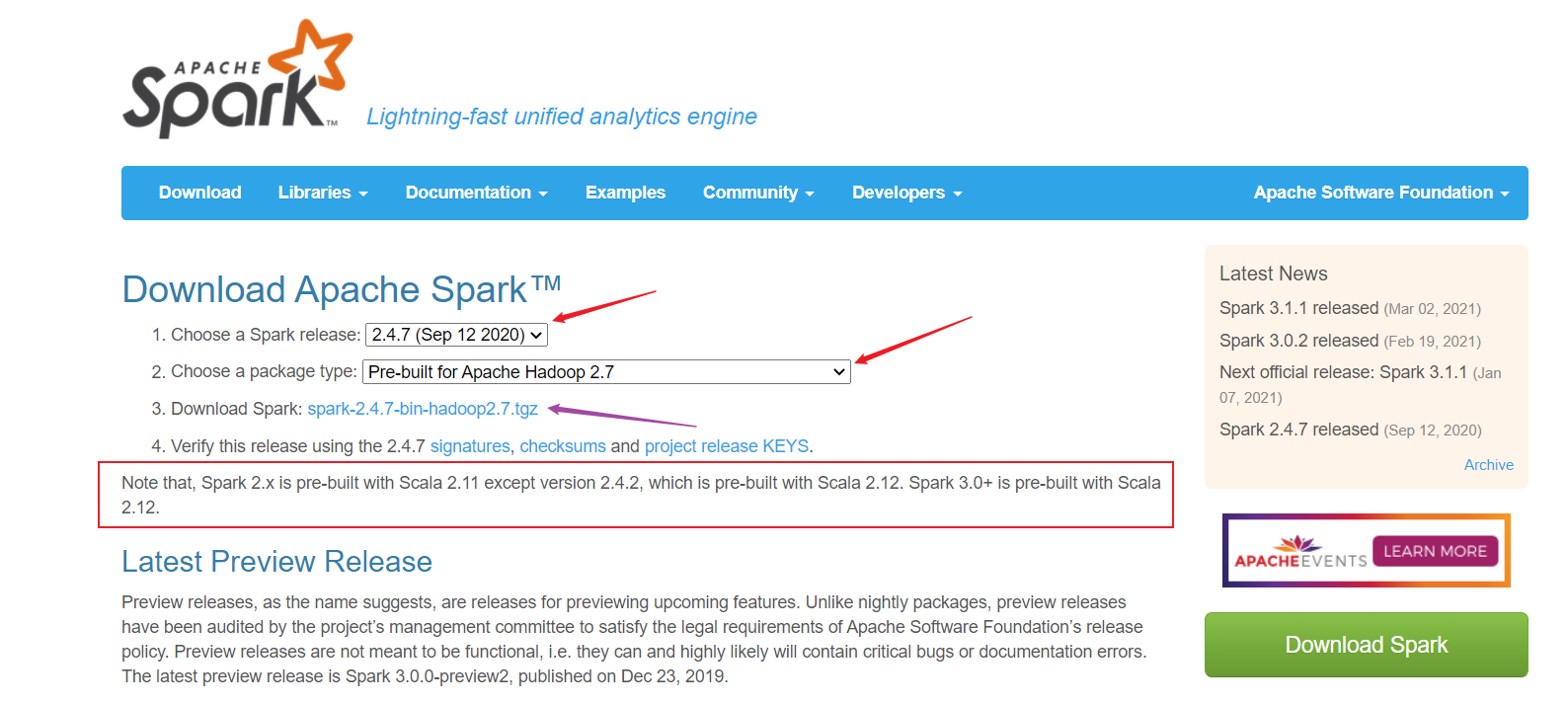
1.选择相应的版本后点击紫色箭头会出现清华镜像的下载地址,复制链接地址在虚拟机中通过wget下载,具体操作如下:
注意:这里我开始选择2.4.7版本的Spark,在运行程序时会与原视频教程所给出依赖的版本不一致,为简单起见,选择与原视频教程相同的Spark版本,即Spark2.1.1
下载地址为:https://archive.apache.org/dist/spark/spark-2.1.1/spark-2.1.1-bin-hadoop2.7.tgz
1 | 下载Spark |
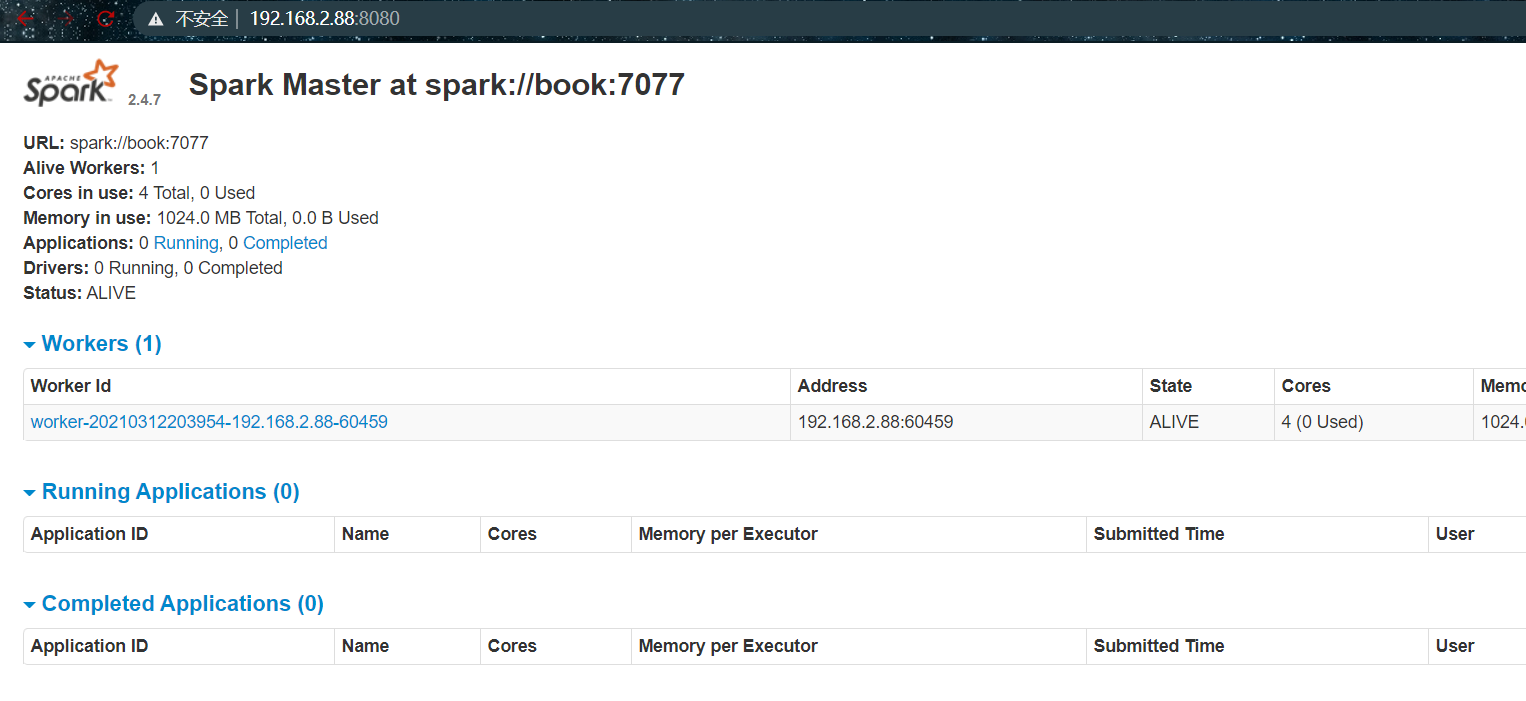
2.上述操作完成后,启动Spark:
./sbin/start-all.sh
启动时会让输入root账户密码
3.此时访问http://192.168.2.88:8080
4.Spark关闭命令
./sbin/stop-all.sh
5.Spark安装完成!
4.安装Redis
1.下载Redis安装包
wget http://download.redis.io/releases/redis-4.0.2.tar.gz
2.解压
tar -zxvf redis-4.0.2.tar.gz
3.重命名
mv redis-4.0.2 redis
4.进入Redis源码目录
cd redis
5.安装编译软件GCC
yum install -y gcc
如果这里安装失败,出现yum的错误,可参见问题文档部分的说明
6.make
7.cd src
8.make install
9.将redis根目录下的redis.conf复制到/etc/下
10.vim /etc/redis.conf
1 | daemonize yes |
11.运行redis,在/redis/src目录下
redis-server /etc/redis.conf
12.进入redis
redis-cli
13.停止redis
redis-cli shutdown
14.完成
5.安装Zookeeper
官网下载地址:http://archive.apache.org/dist/zookeeper/zookeeper-3.4.10/
下载Zookeeper安装包
wget http://archive.apache.org/dist/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz解压
tar -zxvf zookeeper-3.4.10.tar.gz重命名
mv zookeeper-3.4.10 zookeeper进入Zookeeper根目录并创建data数据目录
cd zookeepermkdir data复制Zookeeper配置文件
cp ./conf/zoo_sample.cfg ./conf/zoo.cfg修改Zookeeper配置文件
vim ./conf/zoo.cfg1
2#将dataDIr修改为刚刚创建的data目录路径
dataDir=/usr/local/zookeeper/data
启动Zookeeper服务
./bin/zkServer.sh start查看Zookeeper服务
./bin/zkServer.sh status停止Zookeeper服务
./bin/zkServer.sh stop
6.安装Kafka
下载Kafka安装包
wget https://archive.apache.org/dist/kafka/0.10.2.1/kafka_2.12-0.10.2.1.tgz解压
tar -zxvf kafka_2.12-0.10.2.1.tgz重命名
mv kafka_2.12-0.10.2.1 kafka进入Kafka根目录并修改配置文件
cd kafkavim ./config/server.properties1
2
3
4添加如下内容
host.name=book
port=9092
zookeeper.connect=book:2181启动Kafka服务
注意!启动Kafka之前需要启动Zookeeper服务
./bin/kafka-server-start.sh -daemon ./config/server.properties关闭Kafka服务
./bin/kafka-server-stop.sh
7.安装Flume
下载Flume安装包
wget http://archive.apache.org/dist/flume/1.8.0/apache-flume-1.8.0-bin.tar.gz解压
tar -zxvf apache-flume-1.8.0-bin.tar.gz重命名
mv apache-flume-1.8.0-bin flume等待系统部署


