
Python深度学习
神经网络的数据表示
标量(0D张量)
仅包含一个数字的张量叫作标量(scalar,也叫标量张量、零维张量、0D张量)
1 | import numpy as np |
向量(1D张量)
数字组成的数组叫作向量(vector)或者一维张量(1D张量)
1 | x = np.array([12,3,6,14,7]) |
这个向量有5个元素,称为5D向量。5D向量只有一个轴,沿着轴有5个维度,而5D张量有5个轴(沿着每个轴可能有任意个维度)
维度(dimensionality)可以表示沿着某个轴上的元素个数
矩阵(2D张量)
向量组成的数组叫作矩阵(matrix)或二维张量(2D张量)
1 | x = np.array([ |
张量的关键属性
- 轴的个数。如3D张量有3个轴,矩阵有2个轴,在
Numpy库中也叫ndim - 形状。是一个整数元组,表示张量沿每个轴的维度大小,如矩阵(3,5)、3D张量(3,3,5);向量的形状只包含一个元素,如(5,);标量的形状为空,即()
- 数据类型。在
Python库中也叫dtype。
例如在MNIST数据集中
1 | train_images.ndim # 3 |
即train_images是一个由8位整数组成的3D向量,仔细来讲,是60000个矩阵组成的数组,每个矩阵由28x28个整数组成。
在Numpy中操作张量——张量切片操作
1 | # train_images.shape = (60000, 28, 28) |
a:b表示切片沿着每个张量轴的起始索引a和结束索引b,:表示选择整个轴
数据批量
深度学习的所有数据张量的第一个轴都是样本轴(simple axis 也叫样本维度),在MNIST数据集中,样本就是数字图像。一般深度模型不会同时处理整个数据集,而是将数据拆分成小批量。对于这种批量,第一个轴叫作批量轴或批量维度。
1 | # MNIST数据集的第一个批量,批量大小为128 |
- 向量数据:2D张量,形状为(samples, features)
- 人口统计数据集,其中包括每个人的年龄、邮编和收入,每个人可以表示为3个值的向量,而整个数据集包含100000个人,因此可以存储在形状为
(100000, 3)的2D张量中 - 文本文档数据集,将每个文档表示为每个单词在其中出现的次数,每个文档可以被编码为包含20000个值的向量,整个数据集包含500个文档,因此可以存储在形状为
(500, 20000)的张量中
- 人口统计数据集,其中包括每个人的年龄、邮编和收入,每个人可以表示为3个值的向量,而整个数据集包含100000个人,因此可以存储在形状为
- 时间序列数据或序列数据:3D张量,形状为(samples,timesteps,features)
- 股票价格数据集,每一分钟,将股票的当前价格、前一分钟的最高价格和前一分钟的最低价格保存下来。因此每分钟被编码成一个3D向量,整个交易日被编码为一个形状为(390,3)的2D张量,而250天的数据就可以保存为形状为
(250, 390, 3)的3D张量中 - 推文数据集,将每条推文编码为280个字符组成的序列,每个字符又来自128个字符组成的字母表。每个字符编码为128的二进制向量,每条推文编码为形状为
(280, 128)的2D张量,而包含100万条推文的数据集可以编码为形状为(100000, 280, 128)的张量
- 股票价格数据集,每一分钟,将股票的当前价格、前一分钟的最高价格和前一分钟的最低价格保存下来。因此每分钟被编码成一个3D向量,整个交易日被编码为一个形状为(390,3)的2D张量,而250天的数据就可以保存为形状为
- 图像:4D张量,形状为(samples,height,width,channels)或(samples,channels,height,width)
- 图像通常具有三个维度:高度、宽度和颜色深度。灰度图像(如MNIST数字图像)只有一个颜色通道,因此可以保存在2D张量中。按照惯例,图像张量始终是3D张量。如果图像大小为256x256,那么128张灰度图像组成的批量可以保存在形状为
(128, 256, 256, 1)的张量中
- 图像通常具有三个维度:高度、宽度和颜色深度。灰度图像(如MNIST数字图像)只有一个颜色通道,因此可以保存在2D张量中。按照惯例,图像张量始终是3D张量。如果图像大小为256x256,那么128张灰度图像组成的批量可以保存在形状为
- 视频:5D张量,形状为(samples,frames,height,width,channels)或(samples,frames,channels,height,width)
- 视频可以看作是一系列帧,每一帧都是一张彩色图像。由于每一帧保存在形状为(height, width, color_depth)的3D张量中,因此一系列帧保存在(frames, ,height,width,color_depth)的4D张量中。例如一个以每秒4帧采样的60秒视频片段,视频尺寸为144x256,这个视频共有240帧,形状为
(4, 240, 144, 256, 3)
- 视频可以看作是一系列帧,每一帧都是一张彩色图像。由于每一帧保存在形状为(height, width, color_depth)的3D张量中,因此一系列帧保存在(frames, ,height,width,color_depth)的4D张量中。例如一个以每秒4帧采样的60秒视频片段,视频尺寸为144x256,这个视频共有240帧,形状为
广播
较小的张量会被广播,以匹配较大张量的形状,包含以下两步:
- 向较小的张量添加轴,使其ndim与较大的张量相同
- 将较小的张量沿着新轴重复,使其形状与较大的张量相同
例如,X.shape=(32, 10),Y.shape=(10, ),首先将Y变为Y.shape=(1, 10),再将其沿着新轴重复32次得到Y.shape=(32, 10)
张量变形
1 | x = np.array(([0, 1], [2, 3], [4, 5])) |
神经网络剖析
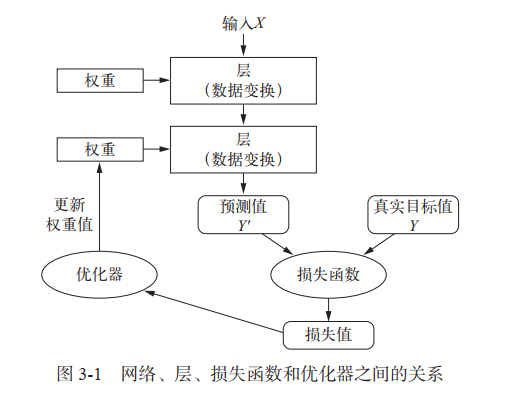
层:深度学习的基础组件
- 2D张量通常用密集连接层(也叫全连接层、密集层),对应Keras的Dense类来处理
- 3D张量通常用循环层,对应Keras的LSTM类来处理
- 4D张量通常用二维卷积层,对应Keras的Conv2D来处理
模型:层构成的网络
深度学习模型是层构成的有向无环图。最常见的就是层的线性堆叠,将单一输入映射为单一输出。常见的网络拓扑结构还有双分支网络、多头网络、Inception模块
损失函数与优化器:配置学习过程的关键
- 损失函数(目标函数)——在训练过程中需要将其最小化,衡量当前任务是否已经成功完成
- 优化器——决定如何基于损失函数对网络进行更新,执行的是随机梯度下降(SGD)的某个变体


